Which AI Bottleneck Matters Most Right Now?

The most important question in AI investing right now is not who has the best model. It is what the system can physically support — and which constraint is most underpriced.
Dylan Patel, founder of SemiAnalysis, lays out this framework on the Dwarkesh Podcast. His argument: AI does not have one bottleneck. It has a sequence of them — and the important question is always which one matters most right now, which one is coming next, and which one sets the outer limit on the whole system.
This is still an infrastructure story. But in Patel’s framing, it is becoming more of a semiconductor manufacturing story than a construction story.
The Scale of the Buildout
Hyperscaler capex is running at $660-750B in 2026 — up 67% year-over-year. Cloud revenue growth is 25-30%. The capex-to-revenue ratio has hit 45-57%, which is historically unsustainable. Microsoft reports $80B in Azure backlog. The market keeps asking whether capex will slow down. So far, the answer is no.
The demand side is not in question. OpenAI hit $25B in annualized revenue (ARR) by February 2026, up from $6B in 2024. Anthropic surged to $19B ARR, up from $9B at the end of 2025. These are the fastest-scaling software businesses in history, and they are the primary drivers of compute demand going forward.
That is what makes Patel’s framework useful. The question is not whether AI demand is strong. It is which part of the system is failing to keep up with that demand — and who owns the bottleneck.
The Bottleneck Sequence
Now: The Deployment Constraints
These are the bottlenecks the market is focused on: CoWoS packaging, data center construction, power availability. They are serious — TSMC’s CoWoS capacity remains sold out through 2026, Vertiv’s organic orders surged 252% in Q4 2025. But Patel’s argument is that the biggest bottleneck is already shifting past them.
His point is that these sit higher in the stack, have simpler supply chains, and can be expanded with enough capital and execution. That does not mean they are easy, and it does not mean they stop being bottlenecks. It means he views them as more tractable than semiconductor manufacturing itself.
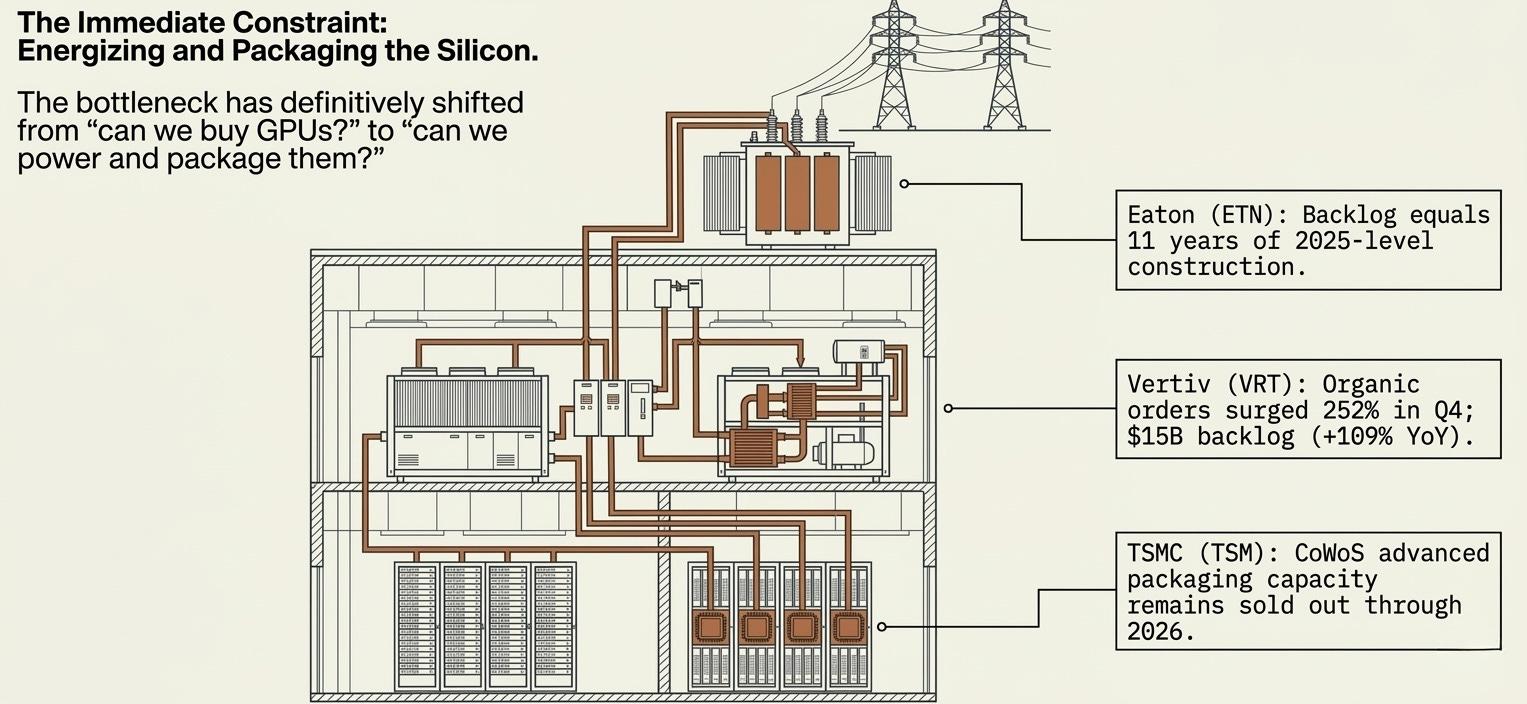
Data centers can be built in less than a year. Power — where Patel parts company with the “AI runs out of watts” crowd — can be sourced flexibly through industrial gas turbines, solar, nuclear, grid expansion, even ship engines. GE Vernova booked $2B+ in data center electrification orders in 2025 (3x the prior year) and has only addressed roughly 10% of its addressable market. Constellation Energy has nuclear PPAs contracted directly with hyperscalers. GPUs are sitting idle due to power constraints, not demand constraints. These are real bottlenecks with real pricing power — but in Patel’s framing, they are deployment constraints, not structural ceilings. Difficult but addressable with enough capital, risk-taking, and engineering effort.
The trade: Two clusters, different risk profiles.
The packaging and inspection names — TSMC (TSM), KLA (KLAC), Camtek (CAMT) — own the CoWoS chokepoint directly. TSMC controls roughly 60% of advanced packaging capacity and is embedded in every leading GPU shipment. KLA and Camtek sit on the yield management side: as CoWoS complexity increases, inspection becomes more critical and more recurring. These are not cyclical equipment names — they are process-critical infrastructure with multi-year demand visibility.
The power and electrical names — GE Vernova (GEV), Eaton (ETN), Vertiv (VRT), Constellation Energy (CEG) — own the constraint between “GPU purchased” and “GPU producing revenue.” Vertiv’s $15B backlog is up 109% year-over-year. Eaton’s backlog equals 11 years of 2025-level construction. The market still prices some of these like industrials. The backlog data says otherwise.
The honest risk: Patel views these deployment constraints as solvable. As power and packaging bottlenecks ease, the market will rotate toward the deeper constraints. These names have durable cash flows for now, but the long-term compounding story sits further down the stack.
Next: Fabs, Clean Rooms, and the Memory Crunch
The system has shifted from deployment chokepoints into something harder: physical semiconductor capacity. Fabs are the most complex buildings humans make, with lead times of two to three years. And the industry underbuilt when memory economics were weak — vendors halted new fab construction in 2023 when they were losing money. Micron’s own supply roadmap shows how long the lag really is: first wafer output from Idaho is expected in mid-calendar 2027, the Tongluo site supports meaningful shipments in fiscal 2028, Singapore HBM packaging is expected to contribute meaningfully in calendar 2027 (per prior guidance), and a new Singapore NAND fab is not expected to produce wafers until the second half of 2028.
This is what is actually driving the memory crunch. It is not just that HBM is tight. There is literally nowhere to place the manufacturing tools needed to scale production.
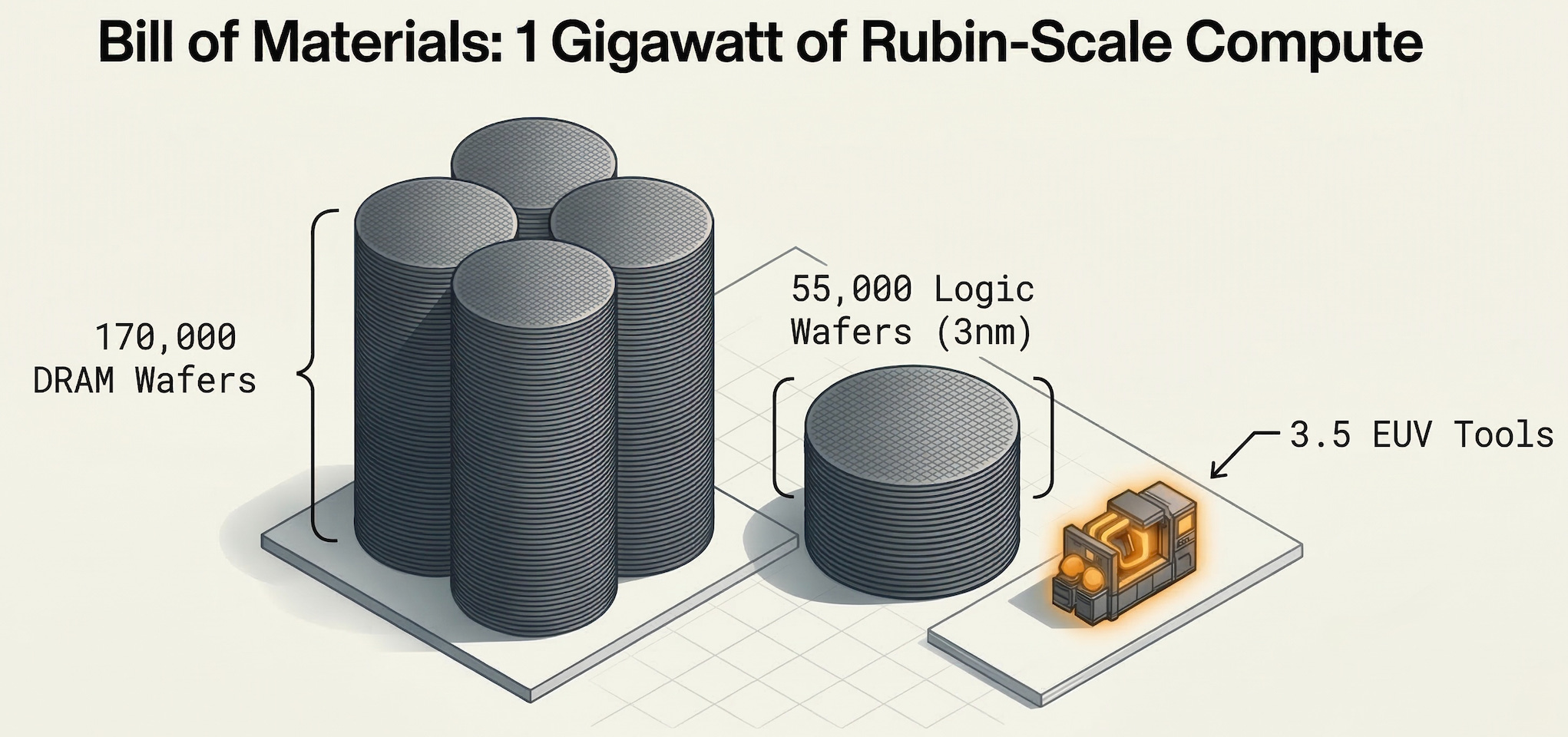
One gigawatt of Rubin-scale AI compute requires approximately 170,000 DRAM wafers (Memory), plus roughly 55,000 wafers of 3nm logic (GPU). Memory is not riding alongside the GPU story. It is the GPU story — just measured in a different unit. And the supply side is an oligopoly:
HBM consumes roughly 3x the wafer capacity per gigabyte versus commodity DRAM — widening toward 4x with HBM4. AI is expected to consume 20% of total global DRAM wafer capacity in 2026. DRAM contract prices are up 40-70%.
Micron’s latest quarter makes Patel’s point more concrete. The company now says both DRAM and NAND supply-demand conditions should remain tight beyond calendar 2026. More importantly, management explicitly tied the DRAM constraint to cleanroom shortages, long construction lead times, a higher HBM trade ratio, and declining bits per wafer from node migrations. That is almost a public-company version of Patel’s framework.
We are looking at a memory supercycle, not a normal cyclical upswing. The demand curve rises hard and fast if compute roadmaps hold. Supply is concentrated in three players maintaining discipline. And the missing fabs mean this crunch cannot be solved quickly — the capacity decisions that would have eased it needed to happen two years ago.
The trade: Three names, three different ways to own the same thesis.
Micron (MU) is the cleanest US public exposure, and the latest quarter materially strengthened the case. Fiscal Q2 revenue reached $23.86B with non-GAAP gross margin at 74.9%, and Q3 guidance points to roughly $33.5B of revenue with gross margin around 81%. DRAM inventory days remain especially tight at below 120 days, and Micron now expects fiscal 2026 capex to come in above $25B as it pushes harder on cleanrooms and long-duration capacity. MU now trades around ~10x forward earnings, and closer to ~5-6x if you annualize the current Q3 run rate.
The most important detail is what drove the quarter. This was not primarily a units story. DRAM bit shipments were up only mid-single digits sequentially, while DRAM prices rose in the mid-60s percentage range. NAND bit shipments were up low-single digits, while NAND prices increased in the mid-to-high 70s percentage range. That is what a bottleneck looks like in financial form: constrained supply showing up first in price, margin, and backlog urgency rather than just shipment volume.
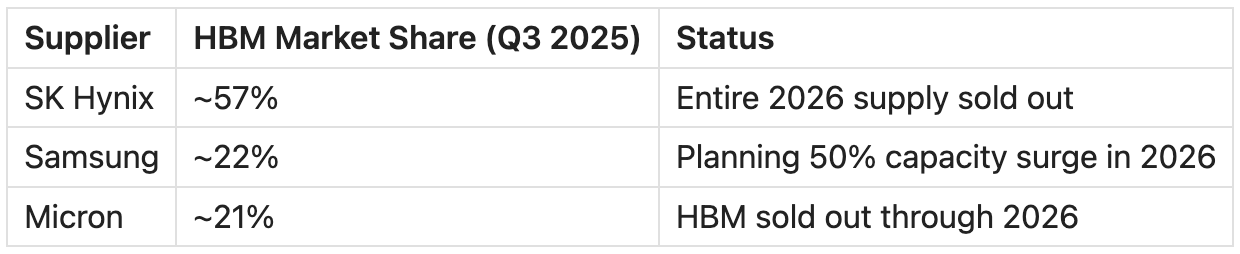
SK Hynix is the dominant player — ~57% of global HBM supply, entire 2026 allocation sold out. The forward P/E sits around ~5x, which prices in Korea market risk and some skepticism about cycle duration. If you believe the supercycle extends past 2026, that discount is the opportunity. Accessible partly via EWY ETF for US investors, or directly on the Korean exchange.
Samsung is the wildcard. They are planning a ~50% capacity increase in 2026. Historically, Samsung has been willing to flood supply to gain share in NAND and commodity DRAM. But so far in this cycle, all three players are raising prices — Samsung and SK Hynix both hiked HBM3E prices ~20% for 2026, and server DRAM is up 60-70%. Samsung’s own exec said demand has already outpaced even the expanded supply. The risk is that discipline breaks as new capacity comes online. It hasn’t yet. Accessible partly via EWY alongside SK Hynix.
Later: The Hard Ceiling — EUV and ASML
By the end of the decade, Patel’s framework says the bottleneck drops to the deepest layer of the supply chain: the production of EUV lithography tools. These are the most complicated machines humans make, built by a single company in Veldhoven, relying on an artisanal supply chain of thousands of specialized suppliers.
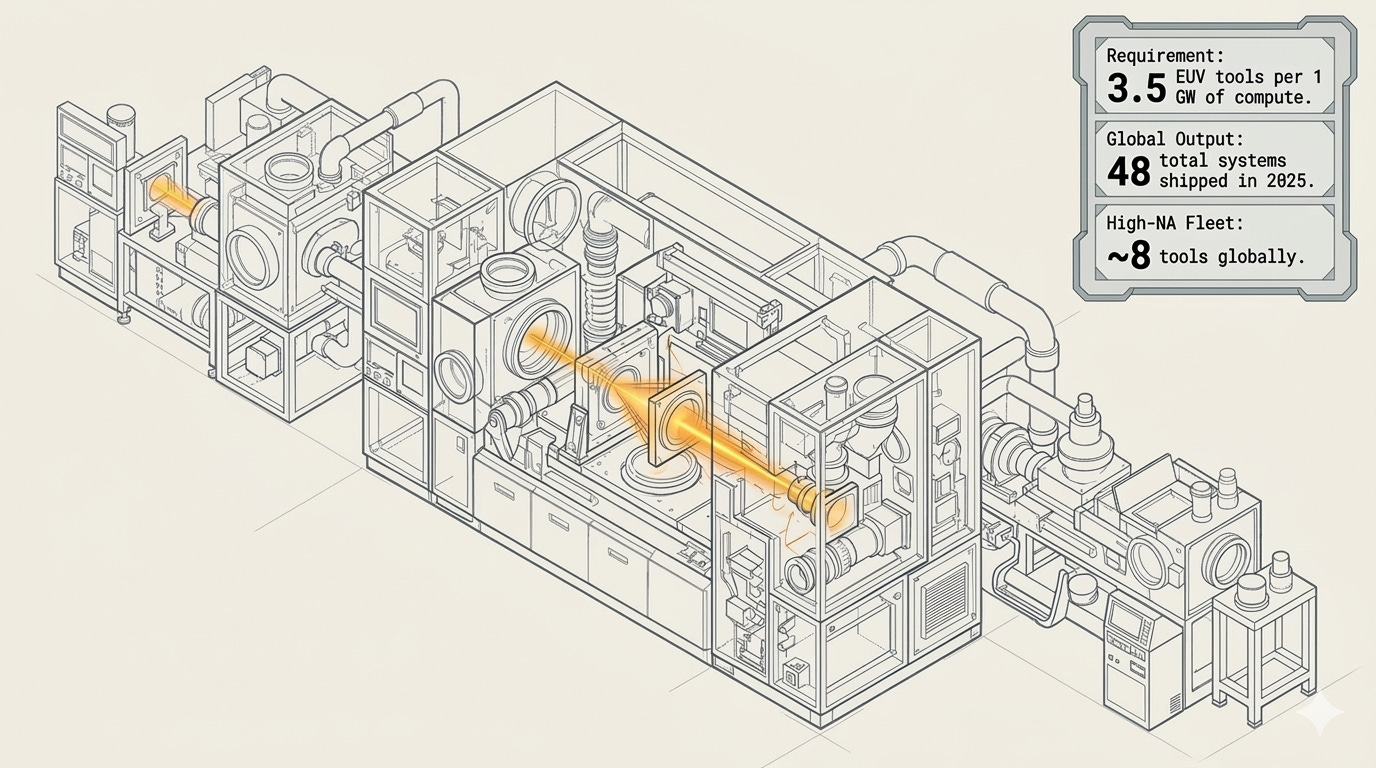
ASML is expected to produce 60-70 EUV tools in 2026 — and will only reach a little over 100 per year by 2030. Each gigawatt of Rubin-scale AI compute requires around 3.5 EUV tools. That math implies an estimated upper bound of roughly 200 gigawatts of AI chip capacity by the end of the decade if enough of that tool base is allocated to AI.
Other constraints can ease. You can build more fabs. You can add power generation. You can expand packaging lines. But you can’t meaningfully accelerate EUV tool production — the ramp is measured in years, not quarters.
High-NA EUV — the next-generation TWINSCAN EXE:5200B at $350M per unit — has only shipped 8 tools in total, with high-volume manufacturing not expected until 2027-2028.
The trade: The 10-year compounder
ASML trades at ~40x forward earnings with a EUR 38.8B backlog. The market understands the monopoly. What it may not fully price is that ASML does not just supply the system — it defines the outer limit of how large the system can get. It doesn’t matter which chip architecture wins, which hyperscaler spends the most, or which AI model is the best. Every leading-edge chip on earth goes through an ASML tool. The question isn’t whether you own it — it’s how much.
One caveat. ASML’s upside is constrained by physics. They can only produce ~60-70 EUV tools per year, ramping to ~100 by 2030. Raising prices helps at the margin — High-NA tools are $370-400M versus $200M for standard EUV — but it does not change the unit constraint that governs the system. Gross margins sit at 52-53% today, guided to 56-60% by 2030. That is gradual expansion, not a step function. At ~40x forward earnings, you are paying for a quality compounder where volume is physically capped and margin expansion is slow. The backlog is durable, but the growth rate has a ceiling built into the manufacturing process itself. Size accordingly.
The H100 Argument
One of Patel’s more provocative claims: an H100 may be worth more today than it was several years ago.
Sounds backwards. But think about what an H100 actually is right now — not a depreciating asset on a balance sheet, but productive capital inside a world where models are getting better, inference demand is increasing, and useful AI work per installed accelerator keeps rising. If the software improves faster than supply expands, older hardware appreciates in economic usefulness even as newer hardware arrives.
Jensen Huang’s GTC 2026 keynote reinforces this. The market has shifted from training-heavy to inference-heavy. Every installed GPU is doing more valuable work than it was a year ago — not less.
Traditional compute depreciates. AI compute, in a supply-constrained world with improving models, may not. The installed base matters as much as the new shipment number.
Custom Silicon Is Part of the Map
Google’s TPUs, Amazon’s Trainium, and the custom ASICs that Broadcom and Marvell design for hyperscalers all run through the same physical constraints — CoWoS packaging, DRAM wafers, EUV tools. They change the competitive dynamics within each layer, but they do not escape the constraints.
Broadcom’s AI semiconductor revenue is up 74% year-over-year, with Google and Amazon representing roughly 60% of that AI revenue. Marvell is growing AI silicon revenue 22%. These are not NVIDIA competitors in the traditional sense — they are parallel demand streams through the same constrained supply chain.
The bottleneck framework is not just a bull case for NVIDIA. It is a bull case for the physical supply chain regardless of whether the marginal AI dollar goes to GPUs or custom silicon. TSMC, ASML, Micron, the equipment names — they win either way. The GPU vs. ASIC debate is a distraction from the deeper question, which is whether the fabs and tools exist to build any of it fast enough.
China Is a Question of Timing
Patel does not make a flat claim that the West wins and China loses. His view is more conditional, and it connects directly to the bottleneck framework.
Fast AI progress widens the Western advantage — the leading labs and infrastructure stack pull further ahead. Slower progress gives China time to catch up through manufacturing iteration and system-level adaptation.
The policy landscape adds texture. H200 exports were shifted to case-by-case review in January 2026 — partially reopened, but with conditions. Blackwell and more advanced architectures remain blocked. The AI Overwatch Act would tighten this further, treating AI chips as weapons exports.
The competitive map is shifting. China is making real progress in memory (CXMT), mature-node logic (SMIC), and system-level AI deployment (Huawei Ascend). Where it is not closing the gap is leading-edge logic — and that is exactly where ASML’s EUV monopoly and export controls create the deepest moat.
The faster the frontier moves, the more valuable the bottleneck owners become. Speed is what determines whether the Western infrastructure advantage compounds or narrows.
What Could Break the Thesis
Every thesis has failure modes. Here is where this one breaks:
Capex slows before application revenue catches up. Hyperscaler capex-to-revenue ratios at 45-57% are historically unsustainable. If even one major hyperscaler signals a capex pause, the infrastructure layers reprice quickly.
The inference inflection disappoints. Jensen Huang’s $1T projection covers cumulative chip sales through 2027 across Blackwell and Vera Rubin, underpinned by his view that agentic AI requires significantly more compute and that inference demand is at an inflection point. If agentic workloads do not scale that aggressively, the demand extension that supports the HBM supercycle and NVIDIA’s $1T outlook loses its foundation.
Deployment constraints ease faster than expected. If power, packaging, and construction bottlenecks resolve quickly — as Patel expects they will — the market may reprice those names before the deeper semiconductor constraints become fully visible. The transition from deployment bottleneck to manufacturing bottleneck is where positioning risk lives.
Fab capacity arrives faster than expected. If the fabs halted in 2023 come online ahead of schedule, or if Samsung and SK Hynix accelerate clean room buildouts, the memory crunch eases sooner than the 2027-2028 timeline suggests. Samsung’s planned 50% HBM capacity surge in 2026 is the first test. If DRAM pricing momentum fades materially in mid-2026, the supercycle narrative needs revisiting.
China closes the gap faster than expected. CXMT scaling DRAM production, SMIC advancing to N+2, or Huawei’s Ascend chips gaining meaningful inference share would compress the Western infrastructure premium. The lower-probability but higher-impact version: a genuine breakthrough in domestic EUV or alternative lithography — China has been investing heavily in DUV multi-patterning and homegrown lithography development — that reduces dependence on ASML tools at the leading edge.
What We Are Watching Next
Five items tied to the next reporting cycle:
Micron Q3 FY26 execution against guidance — Management guided to $33.5B of revenue and roughly 81% gross margin. The next question is whether pricing, inventory tightness, and capex commentary keep confirming the supercycle thesis.
ASML Q1 2026 earnings — EUV shipment count and High-NA EUV delivery timeline. Any acceleration in tool shipments changes the logic ceiling math.
Hyperscaler capex commentary (Q1 2026 earnings cycle) — Watch for any signal of capex moderation from Microsoft, Google, Amazon, or Meta. The $660-750B 2026 estimate needs reconfirmation.
DRAM contract pricing in Q2-Q3 2026 — If HBM and DRAM prices plateau, the memory scarcity thesis weakens. If they re-accelerate, the supercycle extends.
NVIDIA Vera Rubin shipment timeline — Any delay or acceleration reshapes the entire demand curve downstream.
Based on Dylan Patel’s interview on the Dwarkesh Podcast. Source: dwarkesh.com/p/dylan-patel
For more on the AI and how we track the stack, visit theupcurious.com.