The Quiet Force Reshaping AI Infrastructure
Why the most important cost driver in AI isn't compute — and what happens when it gets compressed

Most AI infrastructure conversations revolve around compute: how many H100s a hyperscaler has ordered, what NVIDIA’s next chip roadmap looks like, how many exaflops a data centre can deliver. This framing is understandable but incomplete. As AI models get deployed at scale for longer and longer conversations, a different bottleneck is quietly becoming the dominant cost driver in production inference: memory.
Specifically, a component called the KV cache — and the expensive, constrained chip technology required to hold it.
The memory crunch is no longer a niche concern. Micron just reported the strongest quarter in its history. HBM is sold out through 2026 across all three producers. Lead times are years, and the supply side cannot catch up. Everyone knows this part of the story. The harder question is why demand broke so far past what anyone modeled — and whether the efficiency wave building against it will move fast enough to change the investment math.
The Demand Math Broke
The memory demand was based on chatbots. A user sends a message. The model responds. A few thousand tokens. The GPU moves on. Under that model, memory was a commodity input — important but predictable.
Two things broke that assumption simultaneously.
The KV cache explosion. Every transformer stores intermediate results — key and value matrices — for every token in the conversation. Think of it as the model keeping a detailed notepad of everything it has already read, so it only needs to process what is genuinely new. This KV cache lives in HBM, the high-bandwidth memory stacked on the GPU, and it must stay there for the entire session.
The size scales linearly with context length. And context windows have gone from 8K to 200K to 1M in three years. Here is what that does to a single session on a large model:
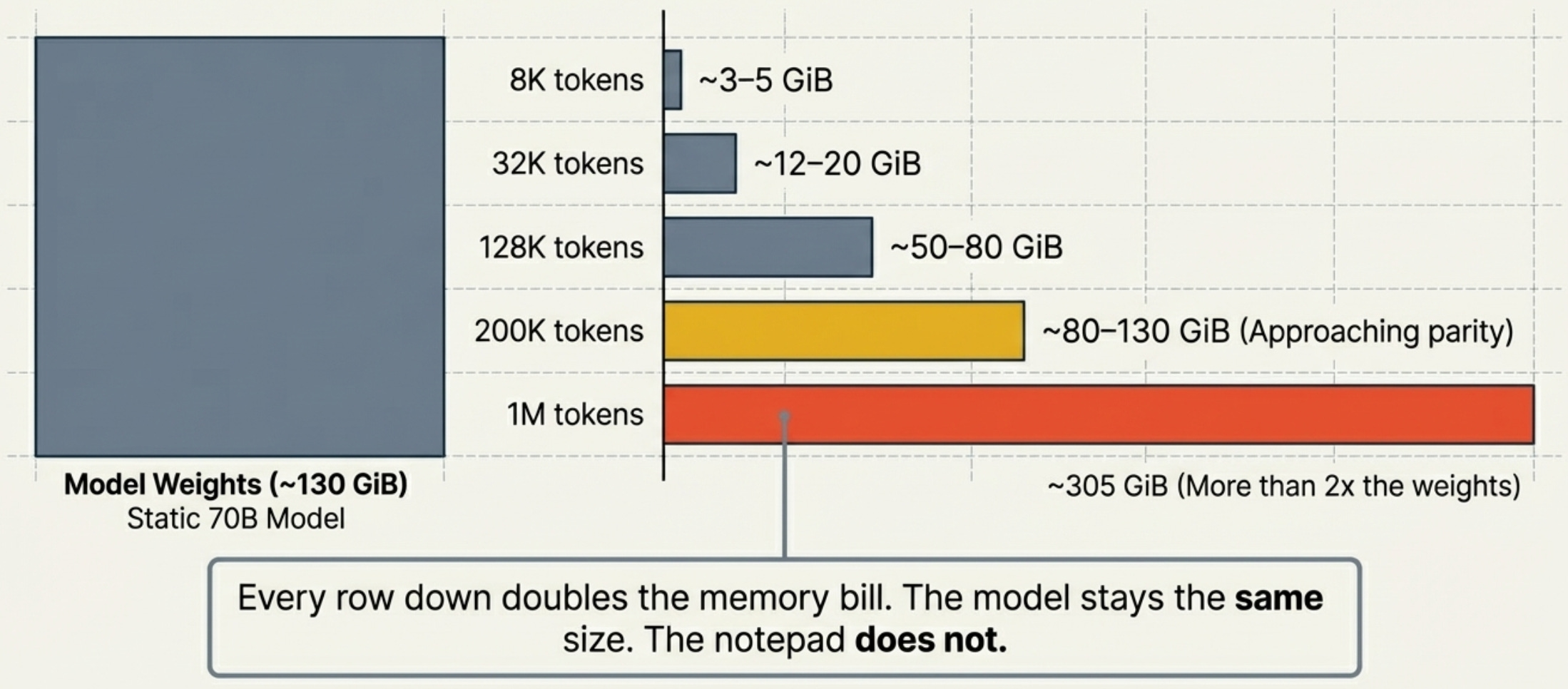
The industry is building toward the bottom of that table. Every row down doubles the memory bill.
Agents changed the unit economics. A chatbot interaction costs under 2,000 tokens. An agentic task — reading a codebase, writing code, running tests, debugging, iterating — costs 100,000 to 500,000 tokens compressed into a single growing context, with the model reasoning internally at every step. The model sees the full history on every forward pass. Run two agents in parallel and you hold two full KV caches in HBM simultaneously. The multiplier versus chatbot economics is not 5x. It is 50 to 100x per unit of user-facing work.
This is not hypothetical. OpenClaw — an autonomous agent that taps multiple models including ChatGPT, Gemini, and Claude, running them continuously and in parallel — has become the hottest productivity trend around the world. OpenRouter data shows weekly token consumption jumping from 1.62 trillion in March 2025 to 20.4 trillion in March 2026. A 12x increase in one year. A human programmer might use several million tokens a day. OpenClaw can burn through billions, with costs reaching thousands of dollars per session.
Jensen Huang made the implication explicit at GTC 2026 on March 16: NVIDIA is reviewing a plan to provide engineers with token allocations equal to half their base salary — roughly $187,500 per engineer per year in token resources. When the CEO of the company that makes the GPUs starts treating tokens as compensation, the demand curve has moved past “early adoption.”
The infrastructure models everyone built before 2024 assumed chatbot economics. The agent era broke that assumption, and nothing about the trajectory suggests it is slowing down.
Micron Just Showed You What a Supply Ceiling Looks Like
We covered Micron’s Q2 FY2026 results in detail last time. The short version: flat volumes, exploding prices. DRAM prices up mid-60s percent sequentially while bit shipments grew only mid-single digits. That is what a physical ceiling looks like — producers cannot ship more, so every dollar of incremental demand shows up in price.
The supply picture has not changed. HBM is sold out through 2026 across all three producers. Micron guided Q3 revenue to $33.5 billion at 81% gross margins, and raised FY2026 capex above $25 billion — money that produces wafers in 2027 and 2028, not now. The hyperscalers have pre-bought the available supply: Microsoft’s 2026 capex is projected above $120 billion, and the Stargate joint venture — backed by SoftBank, OpenAI, Oracle, and others — is a $500 billion, four-year commitment.
The supply crunch is real. But the cause is not primarily a chip story. It is a software story — agents, reasoning, long context — that shows up in the hardware. Micron’s income statement is the proof.
Now the Software Is Attacking the Problem It Created
Here is where it gets interesting.
On March 24, Google Research published TurboQuant. If you only read one AI paper this quarter, make it this one.
The KV cache — the notepad that consumes all that expensive HBM — is traditionally stored at 16-bit floating point precision. TurboQuant compresses it to 3 bits per value, with no retraining or fine-tuning required. That is a roughly 6x reduction in KV cache size. The 70B model that needed 305 GiB of KV cache at 1 million tokens? Now it needs about 50 GiB. A workload that required six H100s can potentially be served on two.
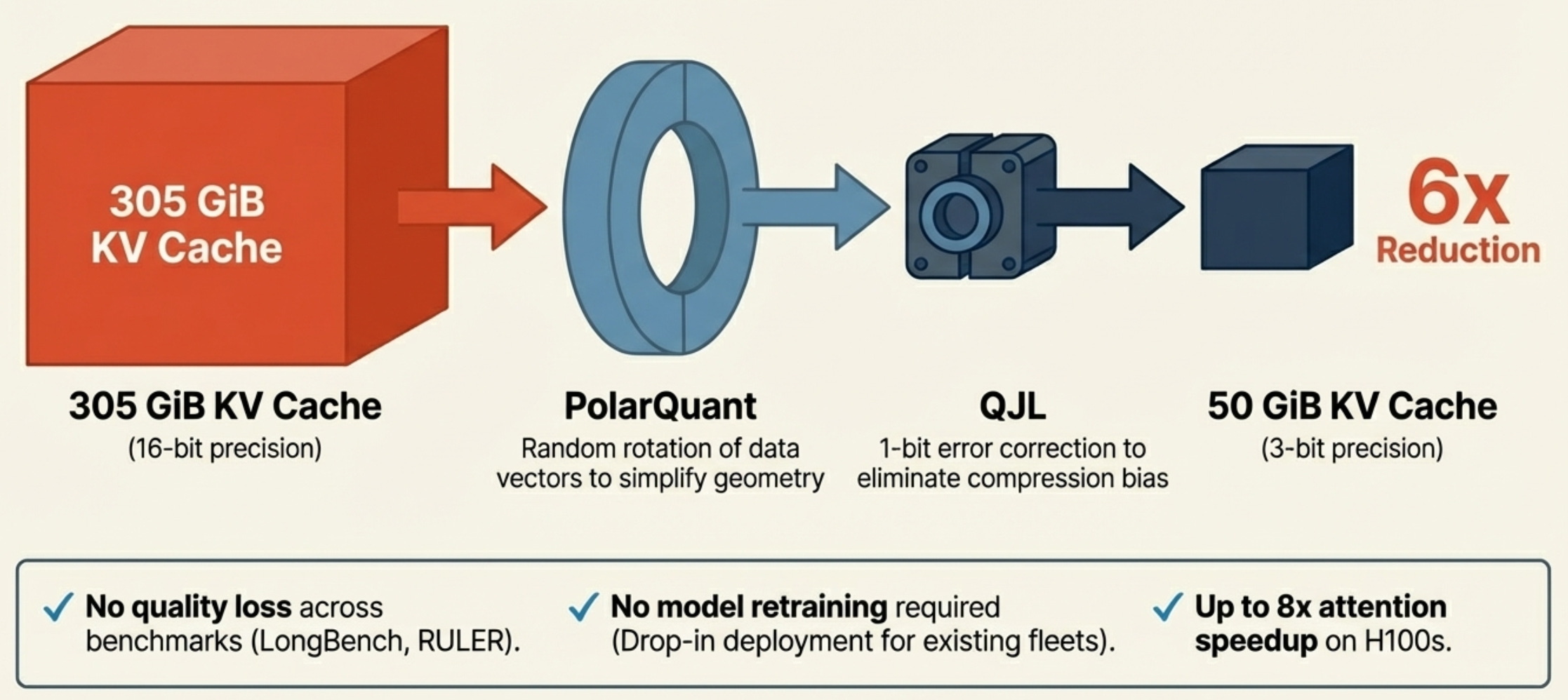
The mechanism is elegant. TurboQuant applies a random rotation to the data vectors (a technique called PolarQuant), which simplifies the geometry enough to apply aggressive quantization. Then it uses a 1-bit error correction algorithm (QJL) to eliminate the bias that aggressive compression normally introduces. The result: 3-bit KV cache that scores identically to full precision across every standard benchmark Google tested — LongBench, Needle in a Haystack, ZeroSCROLLS, RULER. No quality loss. No retraining. Drop-in deployment.
Google tested it on Gemma and Mistral. At 4 bits, TurboQuant achieves up to 8x speedup in computing attention on H100 GPUs versus unquantized keys. The paper will be presented at ICLR 2026.
The “training-free” property is what makes this different from prior KV compression work. Most techniques — KIVI, KVQuant — require model fine-tuning or custom infrastructure. TurboQuant applies at inference time. Any model that already exists can benefit. That means adoption can move fast.
TurboQuant Is Part of a Larger Wave
TurboQuant matters. But zoom out. It is one of three vectors attacking the same problem, and they compound rather than add.
Quantization compresses the bytes. TurboQuant, KIVI, KVQuant, NVIDIA’s NVFP4 — all reduce how many bits each cached value occupies in HBM. This directly shrinks capacity demand.
Sparse attention reduces the reads. Methods like DeepSeek’s NSA architecture and SparQ Attention do not shrink the cache — they reduce how much of it the model reads on each generation step. In long-context inference, the bottleneck is often bandwidth, not capacity. Sparse attention can cut data read per step by up to 8x.
CXL tiering moves cold data off-chip. CXL lets accelerators address large pools of external DRAM at low latency. KV cache that is not actively needed can spill from expensive HBM to cheap rack-level memory. Only the recent tokens stay on-device.
Combine all three: quantize the cache to 3 bits, read only the relevant fraction per step, and offload the cold tail to CXL memory. The maths gets aggressive fast. And none of these techniques existed in production two years ago.
The Market Is Already Repricing This
The tension between demand and compression is not theoretical. The market started pricing it in the week TurboQuant dropped.
Micron hit an all-time high of $471 on March 18, the day it reported the strongest quarter in its history. By March 25 — the day after Google published TurboQuant — the stock had fallen to roughly $382. A 19% drawdown from peak, despite record revenue, record margins, and sold-out HBM through 2026. Western Digital dropped 4.7%. SanDisk fell 5.7%. Samsung and SK Hynix weakened at the same time. Meanwhile, CPU stocks — Intel, AMD — surged as investors recalculated whether “insatiable” HBM demand might be tempered by algorithmic efficiency.
The sell-the-news reaction after earnings was predictable. The acceleration after TurboQuant was not. The market is telling you it heard the compression thesis — and it moved before most analysts had read the paper.
The standard memory cycle ends when demand cools or supply catches up. What makes this cycle different is that both sides are moving simultaneously — and in tension.
On the demand side, the forces are structural, not cyclical. KV cache requirements grow with every context window expansion, and context windows keep expanding. Agents consume more tokens as the technology matures, not fewer — longer loops, larger codebases, more parallel sessions. These are new floors that compound.
On the compression side, TurboQuant-class innovations are also structural. Training-free, drop-in deployment means adoption can move faster than traditional semiconductor cycles. And the compression vectors compound with each other.
So the question becomes: which force wins, and when does it flip?
Through 2026–2027, the demand side wins. Supply is already sold out. Compression techniques take time to deploy at scale across production inference stacks. Micron trades at roughly 10x forward earnings — a multiple that prices a cyclical peak, not a supercycle. The memory names still have the better near-term visibility.
From 2028 onwards, the compression side gets heavier. If TurboQuant-class techniques deploy broadly and CXL tiering becomes production-standard, the per-token HBM demand equation shifts. Total HBM demand probably still grows — AI workloads are still compounding — but the growth rate decelerates. SK Hynix’s pricing power compresses. Samsung, which has lagged on HBM yield and quality, gets hit at the worst time.
So Is This a Buy?
The memory crunch thesis is not broken. But it is no longer open-ended.
Start with what has not changed. HBM is sold out through 2026. Micron just guided $33.5 billion in Q3 revenue with 81% gross margins. The hyperscalers have pre-committed hundreds of billions in infrastructure capex against agentic workloads that are still ramping. TurboQuant is a research paper presented at a conference — it is not yet running in production inference at any major provider. The gap between “published” and “deployed at scale across Google, Microsoft, Amazon, and Meta’s inference fleets” is measured in quarters, probably years.
Micron at ~$382, down 19% from its all-time high with the strongest earnings in its history behind it and sold-out supply in front of it, looks like a buy on a 12-month view. The market is pricing TurboQuant’s impact as if it will compress HBM demand tomorrow. It will not. The production deployment timeline gives the memory names at least four to six more quarters of pricing power before compression can realistically dent contract economics.
he compression wave introduces a time dimension that did not exist six months ago. The near-term supply picture is clear; the 2028 picture is not. Trade accordingly.
Here is how I think about Micron at this junction:
Micron (MU) — a tactical trade, not a thesis reset. The fundamentals have not deteriorated: 10x forward earnings, Q3 guidance implying acceleration, sold-out supply through 2026. The 19% drawdown looks like the market front-running a risk that is real but not imminent. The compression wave will matter — just not in the next four to six quarters. That window is the trade. The risk is that the re-rating sticks regardless of earnings, and the multiple stays compressed even as the business keeps growing. Size accordingly.
The names that win regardless. The more interesting positioning might be the companies that benefit whether demand or compression dominates:
Teradyne (TER) — semiconductor test equipment. AI chips require ~10x more test time per die than prior generations. HBM4 is a substantially more complex package. Whether HBM demand keeps surging or the industry transitions to more complex, lower-volume HBM at higher ASPs, test intensity per wafer goes up. Teradyne’s demand is driven by complexity, not volume alone.
NVIDIA — the quiet winner of this entire dynamic. Memory efficiency increases GPU utilisation. A more efficient model runs at higher batch sizes and larger contexts on the same hardware. Compression opens markets that were previously too expensive to serve. NVIDIA sells the compute. Cheaper memory makes that compute more useful, not less.
Broadcom and Marvell — the CXL plays. If CXL tiered memory becomes the standard way to handle KV cache overflow, both companies benefit from switching fabric, interconnect, and custom silicon. CXL grows faster if HBM supply stays constrained, because CXL is part of the solution. This is a hedge that does not require the memory crunch to resolve in either direction.
What Could Break This
The demand thesis weakens if:
KV cache compression deploys faster than expected. TurboQuant is training-free and drop-in. If the major inference providers adopt it within quarters rather than years, the per-session HBM demand curve flattens sooner. Watch for API pricing changes at the major labs — falling per-token costs at long context lengths would be the leading signal.
Agent token efficiency improves. The 12x token growth from OpenRouter is real — but a meaningful share of it is architectural slop. OpenClaw sends full conversation history on every request, triggers four to five background API calls per visible response, and pulls unranked context that forces the model to process thousands of tokens it does not need. Engineers are already cutting bills by 90% with basic configuration changes. Prompt caching, model routing, and smarter context management could eliminate 60–80% of current agent token spend without sacrificing quality. The counterargument is Jevons paradox — cheaper tokens historically mean more usage, not less. But the efficiency headroom is large enough to temper any straight-line extrapolation of current demand.
Alternative architectures gain traction. Groq’s SRAM-based LPU design sidesteps HBM entirely for inference. If architectures like this reach commercial scale, they structurally reduce HBM addressable market.
DRAM pricing plateaus in Q2–Q3 2026. If memory prices stop climbing despite supply remaining tight, it signals demand absorption is slowing. This is the simplest and most direct disconfirming indicator.
The compression thesis weakens if:
Hyperscalers reinvest savings into longer contexts rather than banking them. This is what has historically happened — efficiency gains get consumed by expanded capability, not passed through as cost reduction. Google is already testing 10 million token contexts. Llama 4 Scout supports 10 million tokens. If the ceiling keeps rising, compression just enables more demand rather than reducing it.
Quality degradation at extreme compression proves worse in production than in benchmarks. TurboQuant reports zero quality loss at 3 bits in controlled tests. Production workloads at scale, with adversarial edge cases and long tails, may be less forgiving.
What We Are Watching
Agentic token consumption. The number to watch is what share of total tokens are consumed by agentic workloads versus simple chat. No lab has published that breakdown yet. When agents cross 50% of token volume at a major provider, the per-session memory profile of the entire fleet shifts dramatically. The first lab to disclose workload composition data will be a significant data point.
TurboQuant adoption velocity. The paper is at ICLR 2026. The question is how fast it moves from research to production inference at Google, and whether NVIDIA integrates similar techniques into TensorRT. If NVIDIA ships native KV cache quantization in its inference stack, adoption accelerates across the entire GPU ecosystem.
DRAM spot pricing — already flattening. This one is worth watching closely. InSpectrum spot data through late March 2026 shows DDR4 16Gb spot prices went near-vertical from October to December 2025 — roughly $5 to $70 — then flatlined from January through March. DDR5 shows the same pattern: stepped up through late 2025, sideways since January at around $32. Three months of zero price momentum after a parabolic move. NAND is lagging by about a quarter — still stepping up, but the slope is flattening. Meanwhile, Micron’s contract prices are still surging (mid-60s% sequential DRAM increases in Q2). That divergence between flat spot and rising contracts is the kind of signal that resolves in one of two directions: either spot is a leading indicator and contract pricing follows down with a lag, or spot is simply too thin to matter because the hyperscalers have pre-bought everything on contract. If spot stays flat through Q2 while contract re-rates lower in Q3, the demand-compression balance may be shifting sooner than the bull case assumes. (Source: inSpectrum Tech Inc DRAM/NAND spot pricing, March 2026)
CXL deployment timelines. Production CXL memory tiering at hyperscaler scale would be a structural shift in how KV cache is served. Broadcom and Marvell benefit directly. HBM-per-GPU requirements decline.
This is part of an ongoing series on AI infrastructure economics. The previous piece covered the full bottleneck sequence: power, packaging, fabs, and EUV
For more on the AI stack and where value flows, visit theupcurious.com.