How Agentic Work Broke Token Pricing
Seven frontier AI models in 18 days. The price per token no longer tells you what a task costs.

The instinct is to rank AI models on price-per-token and SWE-Bench score. That ranking no longer tracks what users actually pay.
Three signals broke at once:
Tokenizers became a hidden price lever. Opus 4.7 raised bills up to 35% without touching the sticker.
Benchmarks became an optimization target. Three Chinese open-weights labs cleared SWE-Bench Pro inside the 18-day window.
The harness layer now drives more cost-per-task variance than the model name does. SemiAnalysis measured Claude Code consuming roughly 25% more input context per output token than Codex on equivalent coding work, on the same underlying model.
The unit enterprises actually care is cost per successful task: token price × tokenizer expansion × harness token behaviour × retries, divided by task success rate.
What Landed in 18 Days
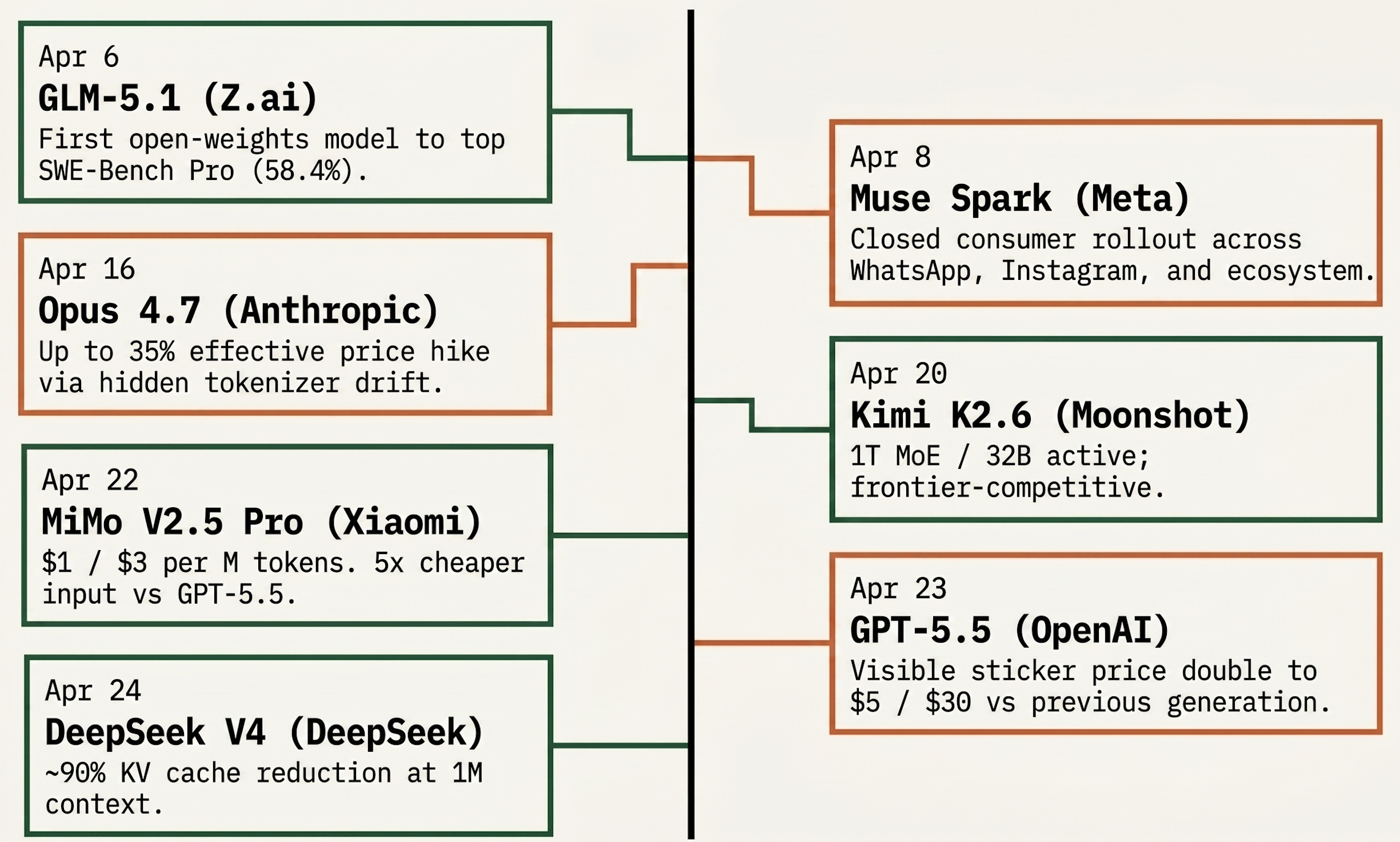
Three patterns visible across the cluster.
Closed labs are raising prices, sometimes invisibly. Opus 4.7 took the hidden route: the sticker did not move, the tokenizer did. GPT-5.5 took the visible route, doubling per-token pricing against GPT-5.4 to $5 / $30, with a Pro tier at $30 / $180. Anthropic’s other play, Mythos (unreleased frontier model), restricted to a small set of launch partners and not slated for general release, has reported SWE-Bench Pro at 77.8%, well above anything publicly comparable. The price moves and the Mythos restriction are two angles on the same play: protect margin where capability is genuinely above the open-weights wave; raise prices where it is not.
Open-weights labs are pricing for adoption, not yield. MiMo V2.5 Pro at $1 / $3 per million tokens is the load-bearing data point on this side, roughly a fifth of GPT-5.5 at frontier-adjacent capability on the public benchmarks. That is not a sustainable yield-curve price. It is a market-entry price: get production workloads onto the platform, accumulate harness-tuning data, price up later. Z.ai and Moonshot are running similar economics. Real per-task gaps are smaller than the 5x sticker once harness behaviour is accounted for, still large enough to move procurement.
Meta added a closed consumer model at the open-weights peak. Muse Spark landed two days after GLM-5.1 became the first open-weights model to top SWE-Bench Pro. That does not mean Meta has abandoned open source. Zuckerberg has said Meta still plans new open-source models. It does mean Meta is separating its consumer-product strategy from the raw model-access strategy: frontier capability can be routed first into Meta AI, with planned rollout across WhatsApp, Instagram, Facebook, Messenger, and Meta smart glasses, without being released as weights on day one. It is a different vertical-integration move from Anthropic’s, on a different end of the stack.
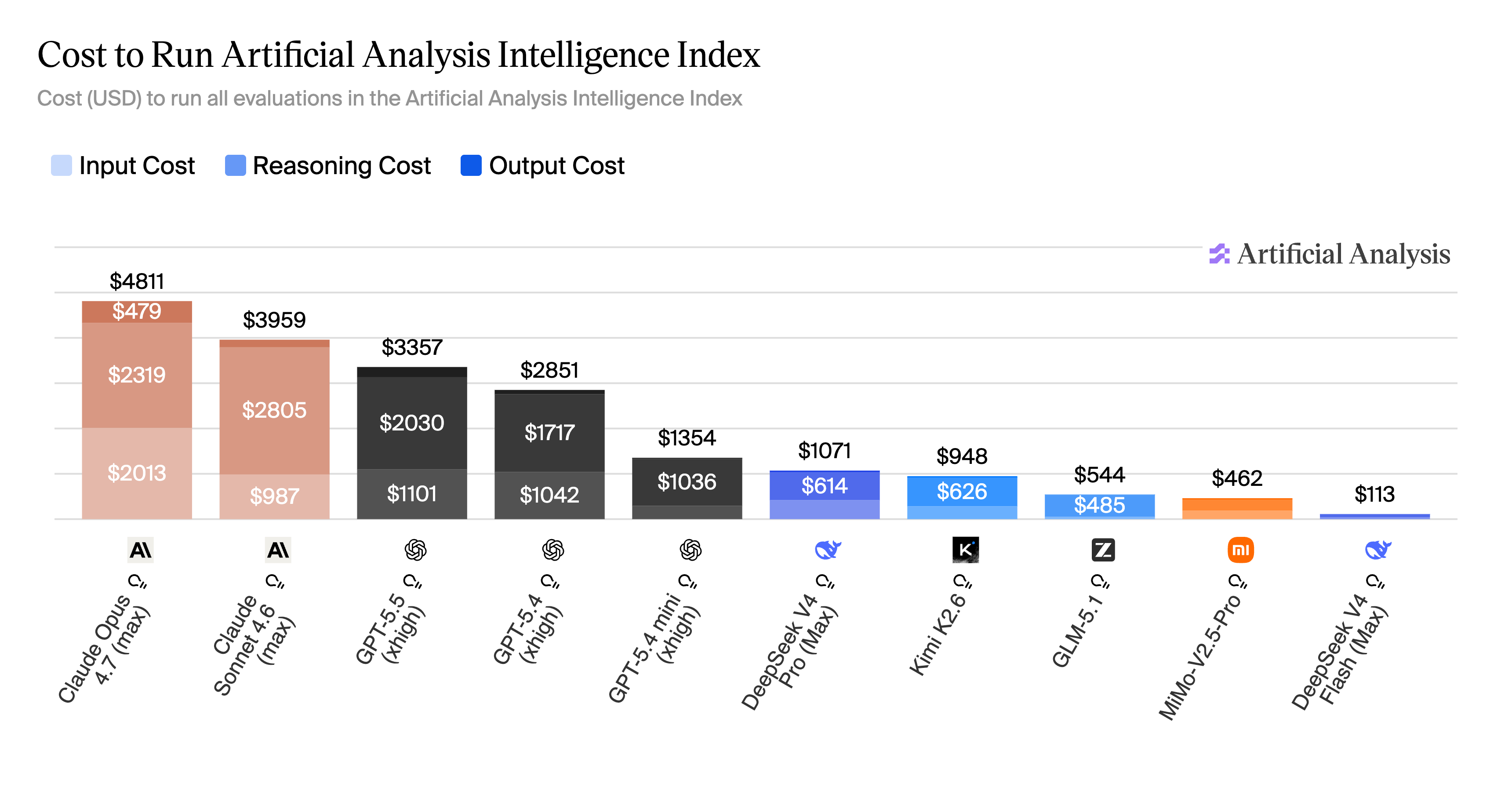
This is the cost-per-task argument in action. Running the full Artificial Analysis Intelligence Index evaluation costs $4,811 on Opus 4.7 max-config and $3,357 on GPT-5.5 xhigh, against $1,071 on DeepSeek V4 Pro Max and $462 on MiMo V2.5 Pro. The closed-source max configurations sit at roughly 10x the open-weights frontier on the same benchmark suite, and reasoning cost dominates that bill: 60–75% of the total on closed-source max configurations, close to zero on the open-weights side. Configuration is itself a cost lever within a single model. GPT-5.5 ranges from $1,199 (medium) to $3,357 (xhigh), a 2.8x spread on the same weights.
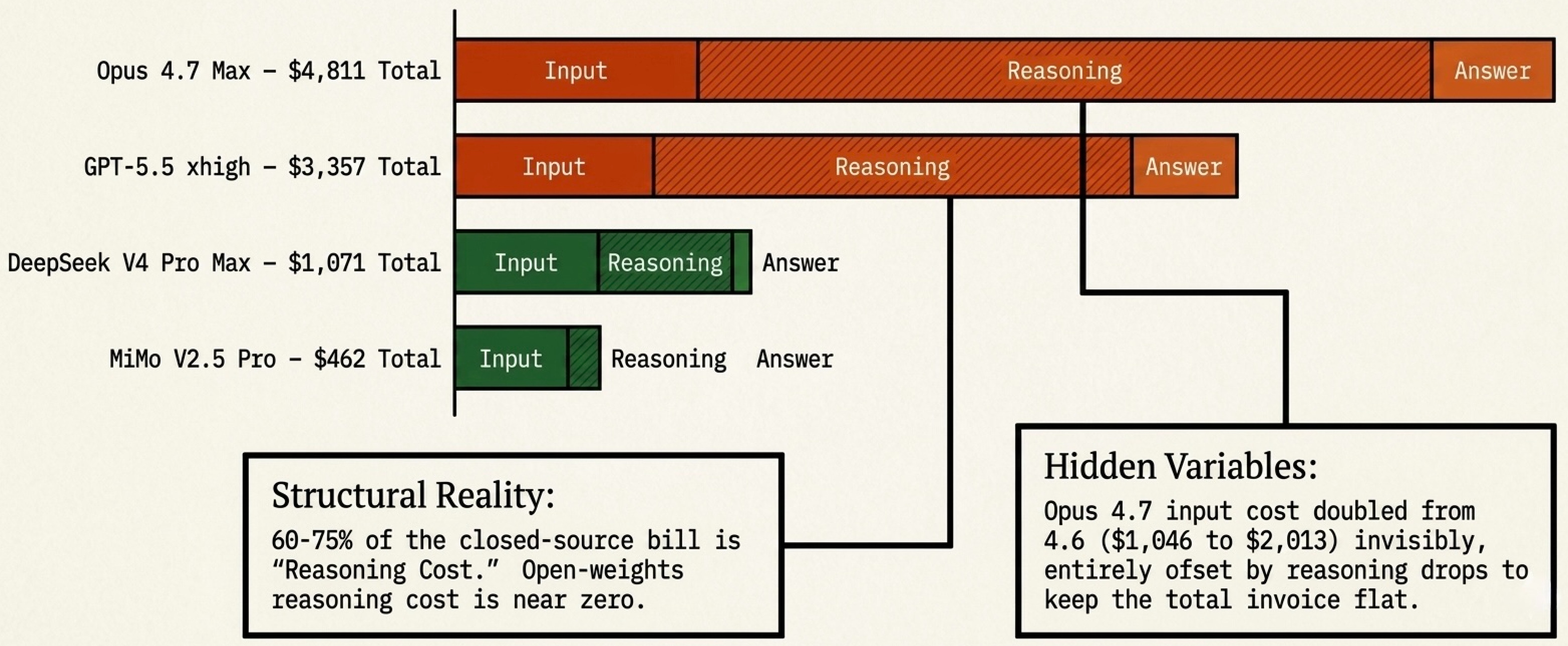
The Public Signal Is Now Broken
Five things have gone wrong with the signals at the same time.
Benchmark optimization has saturated the open-weights cluster. SWE-Bench Pro was meant to be the contamination-resistant successor to SWE-Bench, with private repositories used to keep training data clean. Within months of the benchmark becoming the industry reference, three Chinese open-weights labs have published models that occupy the top of the leaderboard, all within a 18-day window. That is not impossible to achieve honestly, and the underlying capability is real. It also fits the pattern of a benchmark that has become the optimization target rather than the measurement instrument. The contamination asymmetry runs in one direction: open-weights labs face fewer institutional checks on training data composition than closed labs do, and the cost of getting caught is lower. The more defensible read is not that the scores are fake; it is that leaderboard position now needs production evidence before it should be treated as durable capability.
Closed labs curate benchmark framing, too. OpenAI publicly campaigned for SWE-Bench Pro as the right industry benchmark in February 2026, and the GPT-5.5 announcement did publish a SWE-Bench Pro score: 58.6%, with a memorization caveat. That is better than omission, but it does not remove the disclosure problem. Closed labs still choose which benchmarks get headline treatment, which internal evals stay private, and how caveats are framed. SemiAnalysis’s broader read is that Mythos and Opus 4.7 remain stronger in some important zones even where GPT-5.5 looks better on selected public numbers. The benchmark game is asymmetric on both sides. Open-weights labs optimize for the score; closed-source labs optimize the disclosure frame. Both compromise the public signal.
Opus 4.6 and 4.7 had visible production trust issues. Anthropic’s Claude Code product carried three production bugs that affected many users before the fix posted. Engineers using Claude Code through the 4.6 and 4.7 cycle reported behaviour changes that did not match the clean release-note story: more brittle instruction-following, unexpected regressions, and tool-use issues that varied by harness and effort level. The important point is not intent. It is that the closed-source trust premium (the reason an enterprise pays $5 / $25 for Opus rather than $1 / $3 for MiMo) depends on stability, disclosure, and predictable migration behaviour. Anthropic spent some of that premium in this cycle.
Tokenizer drift, in detail. Opus 4.7’s change is the cleanest case. A workload migrated from 4.6 to 4.7 today can cost up to 35% more for the same inputs and outputs, with all of the change driven by how the model encodes text rather than what the model does with it.
Harness as the dominant cost variable. A coding agent does not run a single forward pass. It plans, reads files, drafts, runs tests, reads errors, redrafts. Each step is a token decision driven by the harness: what context to load, when to compact, what tools to call, when to stop. Codex and Claude Code on the same underlying model produce materially different per-task costs. Cursor and OpenCode on the same model produce materially different costs again. The harness is now part of the product, and it is where most of the cost-per-task delta lives. Two of the three inputs to real cost — tokenizer behaviour and harness behaviour — sit outside the standard pricing comparison.
Updating the Demand Engine Thesis
Two weeks ago, Anthropic’s Managed Agents launch read as a vertical-integration play: Anthropic capturing the runtime moat by selling a managed agent platform on top of its model rather than letting customers wire up their own. That framing is intact. The April cluster bounds the upside of that thesis tighter than the prior piece suggested.
Even discounting the benchmark-gaming concern from the prior section, the floor under managed pricing is bounded by two things that do not depend on leaderboard truth: open-weights pricing and architectural memory efficiency. MiMo at $1 / $3 versus GPT-5.5 at $5 / $30 is a procurement decision regardless of who tops SWE-Bench Pro. DeepSeek V4 cutting KV cache by an order of magnitude is structural inference economics regardless of any capability claim. The floor is no longer one open-weights model. It is a wave. GLM-5.1 cleared the closed-source coding leaderboard at zero per-token cost beyond inference compute. Kimi K2.6 followed within two weeks. An enterprise that wanted to run a long-running agent workflow on closed infrastructure two weeks ago was paying to keep HBM pinned for the length of the session. That same enterprise today has at least four credible self-hosting options, three with open weights, one with first-party pricing that approaches commodity.
This does not collapse the managed-runtime business. It bounds the pricing power. Anthropic and OpenAI can charge a premium where reliability, security review, accountability, and integrated tooling matter more than unit cost, which is most regulated enterprises today. They cannot charge an unbounded premium, because the cost of the alternative just dropped sharply on multiple axes simultaneously. The premium is bounded above by what an enterprise can replicate with open weights and competent infrastructure, and that ceiling moved down materially.
Deepseek V4’s reception is the cleanest case of the broken signal. Every public signal interprets this release as underwhelming. The architecture says the opposite.
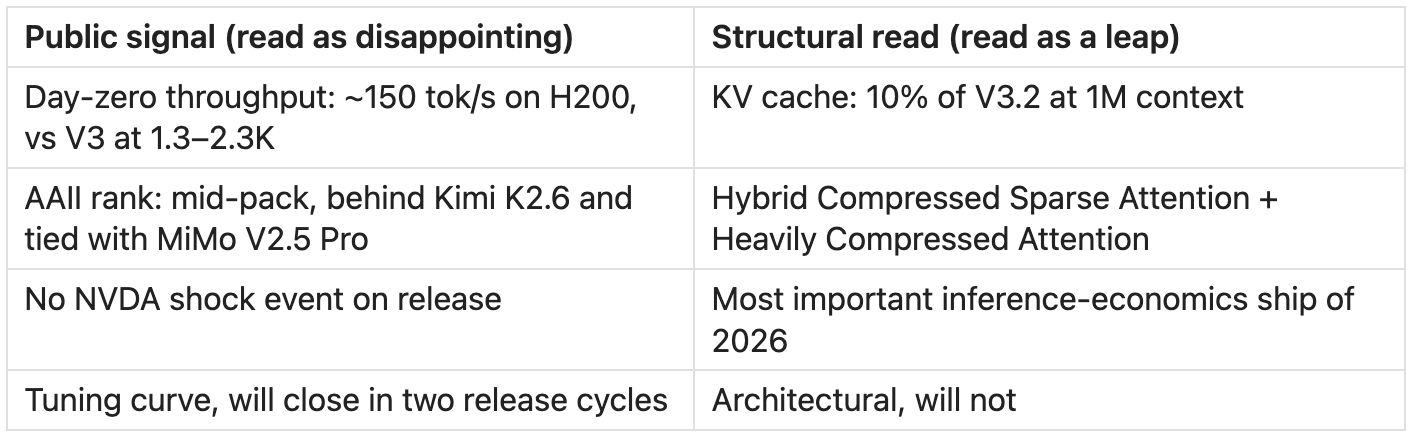
The disappointment narrative is the public signal failing to capture the structural one.
Efficiency, Jevons, and the Demand Engine
The compression wave is real. The demand engine is also real. The empirical question is whether efficiency outpaces usage growth, or usage growth absorbs the efficiency gain.
The OpenRouter scoreboard is the cleanest public signal on this. Weekly token volume on the platform is up roughly four times year-over-year, from approximately 5 trillion in April 2025 to over 20 trillion in April 2026. The fastest-growing behaviour is agentic inference: single requests pushed from thousands of tokens to 100K-1M tokens, run in long sequences with tool calls. That growth happened against continuous efficiency improvement: better quantization, sparse attention, prompt caching, KV compaction. None of it slowed the demand curve.
The composition shift on OpenRouter is the second signal worth holding. Chinese-origin models now account for over 45% of platform traffic, up from under 2% in late 2024. That number reflects two things at once: real-world quality adoption (engineers running production workloads on cheaper open-weights models that perform well enough) and price-driven traffic that does not reflect quality choices. Both interpretations advance the cost-per-task argument: enterprises are increasingly willing to migrate workloads onto cheaper models, either because the quality holds or because the cost differential is large enough to absorb the quality risk.
DeepSeek V4 will follow the same pattern. This is the Jevons shape: cutting long-context memory by an order of magnitude does not deflate inference demand, it expands the set of workloads where million-token context is economically justifiable, which means more million-token sessions, which means more sustained HBM demand in aggregate even as each session uses less HBM per unit of work. Total memory load goes up unless capability ceilings hold demand back, and the demand ceiling has been receding for three years.
The counter evidence worth holding: capability dominance. If Mythos, Opus 4.7, and GPT-5.5 widen the outcome-quality gap meaningfully against open weights (and if benchmark-optimization on the open-weights side reflects gaming rather than real capability), cost-per-task comparisons matter less because only the frontier closed model finishes the job reliably. SemiAnalysis’s read is that the capability gap still applies in narrow zones: Mythos on cybersecurity, Opus on long open-ended tasks, GPT-5.5 on dense reasoning. Outside those zones, the cost frame increasingly drives selection. Leaderboard dominance from the open-weights cluster does not by itself prove the cost frame has won. It does confirm the cost frame is now being seriously tested.
What This Means for Where Value Sits
The thesis from this series holds, with the following updates.
Memory, packaging, and power names: thesis intact and reinforced. Seven frontier-class products land on the same constrained infrastructure. SK Hynix sold out through 2026, Micron sold out through 2026, TSMC CoWoS reserved by NVIDIA. The DeepSeek and MiMo efficiency improvements expand the demand pool rather than relieve the supply constraint. The bottleneck names remain the cleanest public expression of this trade.
Harness layer: analytically real, structurally private. Cursor, Cognition, OpenCode, and the first-party harnesses inside frontier labs are where cost-per-task is determined. There is no clean public-equity expression of this layer today. Watch for acquisitions, IPO filings, and any disclosure of session-level economics. Anthropic’s eventual S-1, rumoured for October 2026, will be the first published view of harness economics from the inside.
Managed-runtime thesis: bounded above by an open-weights wave, not one model. The prior piece’s read on Managed Agents was directionally right. The ceiling on that thesis is now visible and lower than two weeks ago. The product is real, the moat is real, the pricing power is bounded by what an enterprise can replicate with open-weights infrastructure at frontier-adjacent capability, which is now four models, including one (MiMo) with first-party pricing at roughly a fifth of the closed-source frontier.
At risk: API-resold middleware. Companies that built features on top of frontier APIs without owning either the model or the harness layer face compression from both directions. Frontier labs are descending into the harness. Open weights are rising into capability ranges that previously required closed APIs. The middle of the stack is where the squeeze lands first.
Trust premium: under explicit pressure. Open-weights pricing is now low enough and capability close enough that enterprises will require predictable migration behaviour, stable tokenizers, and a low-babysitting harness to justify the closed-source premium. If closed labs spend that capital faster than Mythos-tier capability replenishes it, the cost-per-task argument starts winning workloads where it currently does not.
Subscription pricing is breaking too, for the same reason. Cursor shifted from “unlimited” to capped and usage-metered tiers in 2025 after power users running coding agents burned through subscription compute orders of magnitude faster than the plans were designed to absorb. Claude Pro and Max have weekly limits and throttling on heavy users. ChatGPT Plus has had message caps from the start. GitHub Copilot, Replit, and Cognition’s Devin have all moved toward usage-metered or “premium request” tiers. Per-token pricing breaks the procurement comparison; subscription pricing breaks the consumer plan. Both were structures designed for an earlier consumption pattern, and both are compressing under the same agentic load.
What We Are Watching
Big Tech earnings, in flight now. Meta, Google, Microsoft, and Amazon report through late April and early May. The number that matters is whether 2026 capex guidance moves up against the agent-driven demand signal. Hyperscaler capex revisions are the next confirmation point.
Real-world adoption of the open-weights cluster, and migration patterns inside the closed-source pair. OpenRouter share is the cleanest leading indicator on the open-weights side. If GLM-5.1, Kimi K2.6, and MiMo V2.5 Pro accumulate share on production workloads, not just price-driven test traffic, the benchmark-optimization skepticism gets resolved one way. The companion signal sits inside the closed-source pair: if teams using Claude Code start switching to Codex on GPT-5.5 for execution work, the cost-per-task argument is being priced in real time. If migration stalls because the harness gap closes more slowly than the model gap, the harness layer just got more valuable.
Mythos release timeline. A general-availability date for Mythos would be a meaningful re-rating event for both inference demand and capability competition. It would also be the cleanest counter evidence for the cost-per-task thesis, if Mythos’s capability lead is large enough to make the cost frame irrelevant in the workloads that matter most.
Anthropic S-1 filing. Rumoured for October 2026. The single most informative document this thesis is waiting on. It will resolve the gross-versus-net revenue question, expose session economics, and put the managed-runtime moat on a balance sheet the market can price.
This is part of an ongoing series on AI infrastructure economics. Earlier installments covered the bottleneck sequence, the memory crunch and the compression wave moving against it, and the model race as the demand engine behind the infrastructure thesis. This piece updates the demand engine read for the seven-release April cluster, and bounds the managed-runtime thesis against the open-weights wave.
For more on the AI stack and where value flows, visit theupcurious.com.